今天要做什麼
給一個起始網址(landing page),把頁面上可見的 文字與 href 連結抓下來:
指定最大筆數(避免一次抓太多)
僅保留同網域(或允許多個網域的白名單)
延遲請求(避免過度頻繁)
可輸出成 CSV
會用到
requests:發送 HTTP
bs4 (BeautifulSoup):解析 HTML
urllib.parse:處理網址 & 網域比對
argparse:命令列參數
csv:輸出結果
第一次用請先安裝:
pip install requests beautifulsoup4
程式碼(crawl_titles.py)
把下面存成 crawl_titles.py 放在project 資料夾
import argparse, csv, time, sys
from urllib.parse import urljoin, urlparse
import requests
from bs4 import BeautifulSoup
def same_domain(url: str, allowed: set[str]) -> bool:
netloc = urlparse(url).netloc.lower()
return any(netloc == d or netloc.endswith("." + d) for d in allowed)
def fetch(url: str, timeout=10):
headers = {
"User-Agent": "Mozilla/5.0 (compatible; TinyCrawler/1.0; +https://example.local)"
}
r = requests.get(url, headers=headers, timeout=timeout)
r.raise_for_status()
return r.text
def extract_links(html: str, base_url: str):
soup = BeautifulSoup(html, "html.parser")
results = []
for a in soup.select("a[href]"):
text = (a.get_text() or "").strip()
href = a.get("href")
if not text or not href:
continue
abs_url = urljoin(base_url, href)
results.append((text, abs_url))
return results
def main():
ap = argparse.ArgumentParser(description="抓取頁面上的標題與連結")
ap.add_argument("url", help="起始網址,例如:https://ithelp.ithome.com.tw/")
ap.add_argument("--allow", nargs="*", default=[], help="允許的網域(空白分隔),例如 ithelp.ithome.com.tw ithome.com.tw")
ap.add_argument("--limit", type=int, default=100, help="最多輸出筆數(預設 100)")
ap.add_argument("--delay", type=float, default=1.0, help="請求延遲秒數(預設 1.0)")
ap.add_argument("--out", help="輸出 CSV 檔名(不指定則只印出來)")
args = ap.parse_args()
start = args.url
allowed = set(args.allow) if args.allow else {urlparse(start).netloc.lower()}
try:
print(f"Fetching: {start}")
html = fetch(start)
time.sleep(args.delay) # 禮貌延遲
except requests.RequestException as e:
print("❌ 請求失敗:", e)
sys.exit(1)
pairs = extract_links(html, start)
# 過濾:只保留允許網域、http(s)、去重
seen = set()
cleaned = []
for text, link in pairs:
if not link.startswith(("http://", "https://")):
continue
if not same_domain(link, allowed):
continue
key = (text, link)
if key in seen:
continue
seen.add(key)
cleaned.append({"text": text[:200], "url": link})
if len(cleaned) >= args.limit:
break
if args.out:
with open(args.out, "w", newline="", encoding="utf-8") as f:
w = csv.DictWriter(f, fieldnames=["text", "url"])
w.writeheader()
w.writerows(cleaned)
print(f"✅ 已輸出 CSV:{args.out}({len(cleaned)} 筆)")
else:
for i, row in enumerate(cleaned, 1):
print(f"{i:>3}. {row['text']} - {row['url']}")
print(f"✅ 總筆數:{len(cleaned)}")
if __name__ == "__main__":
main()
執行範例
只看輸出python crawl_titles.py https://ithelp.ithome.com.tw/ --limit 10 --delay 0.5
限制在指定網域,並輸出 CSVpython crawl_titles.py https://ithelp.ithome.com.tw/ --allow ithelp.ithome.com.tw --limit 50 --out links.csv
換個網站(記得改 allow 網域)python crawl_titles.py https://www.python.org/ --allow python.org --limit 40 --out py_links.csv
實作: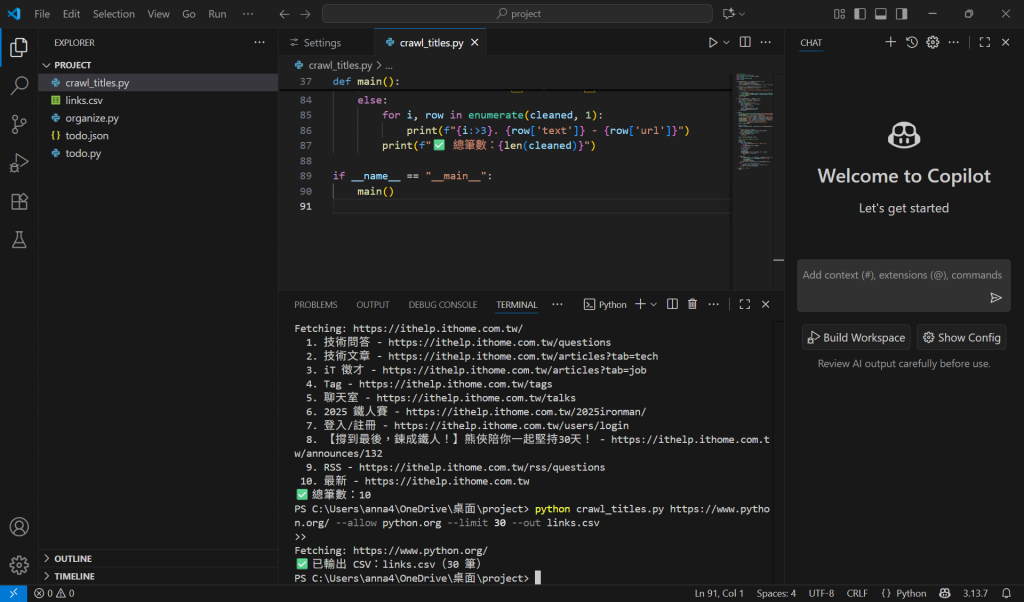
合法爬蟲禮節(最小清單)
尊重 robots.txt:先用瀏覽器看 https://網站域名/robots.txt,確認允許抓的路徑。
加上 User-Agent:程式碼已放入基本 UA。
限速:加入 --delay;大量頁面就提高延遲。
小量測試 → 再擴大:先 --limit 小一點、或先不輸出檔。
只抓公開資訊:不要登入、不要繞過驗證、不要抓個資。
今日重點
Requests + BeautifulSoup 能快速完成單頁資訊擷取
用 urlparse 做網域白名單,避免不小心外連太多
先設 limit、delay 與 allow 是安全穩妥的預設
需要可重複利用的話,直接用 --out 產 CSV
明天我們會做一個 CSV ↔ JSON 轉換器,把資料在兩種格式間快速互轉,並處理常見的編碼/欄位型別問題。
 eyeyeyeye
eyeyeyeye

 iThome鐵人賽
iThome鐵人賽